Orchestrating Spark Jobs with Kubeflow for ML Workflows

This post is about Kubeflow, Spark and their interaction. One year ago, I was trying to trigger a Spark job from a Kubeflow pipeline. It was proving to be a stubborn but exciting problem. The other weekend, I started tinkering with this problem again. In the end, persistence and patience yielded satisfactory results. To skip the intro, click here.
Motivation
Why is it necessary to orchestrate Spark jobs with Kubeflow? Isn’t it sufficient to simply submit these jobs to a Kubernetes cluster and wait till they are finished? The answer of course is, it depends. In the use case I was working on, it was necessary to be able to orchestrate jobs, to make sure resources are fully utilized, and all the processing steps are finished as soon as possible.
A typical Machine Learning (ML) workflow consists of three stages: preprocessing, training, and serving. During preprocessing, data cleaning and data transformations are performed. During the training stage, one or more models are trained. These models are in turn made available to the target audience in the serving stage. The data generated during serving, can be fed back to the pipeline to help improve model accuracy, keep the model relevant and up-to-date as old training data might become irrelevant.

This post is about the preprocessing stage.
The increasing amount of data available as input for ML workflows, increases the need for efficient processing of data. Using bigger machines is expensive and sometimes not possible anymore. Hence, the solution is Distributed Computing. Distributed computing frameworks with time have become more mature and available for a broader audience, besides research or expert data engineers. Naturally, the complexity of the workflows increases as well. On one hand, some workflow steps are dependent on the output of others and have to be executed sequentially. On the other hand, other steps have no such dependencies between them and can be executed in parallel. In this post, I will consider Apache Spark for distributed computing. There are however other alternatives, e.g. Dask, Ray, etc.

In addition to orchestration complexity, data transformations happening outside of the common infrastructure create data silos. Hence, it is important for these workflows to be integrated into the existing infrastructure. This comes with the additional benefit of saving time and money by not providing separate infrastructure. Nowadays, companies use Kubernetes as a platform to run an ample mix of workloads types, and ML workloads should also be one of them.

Is it possible to orchestrate and integrate these workloads in a Kubernetes cluster? Let’s start by taking a look into the tools and concepts involved here.
Spark
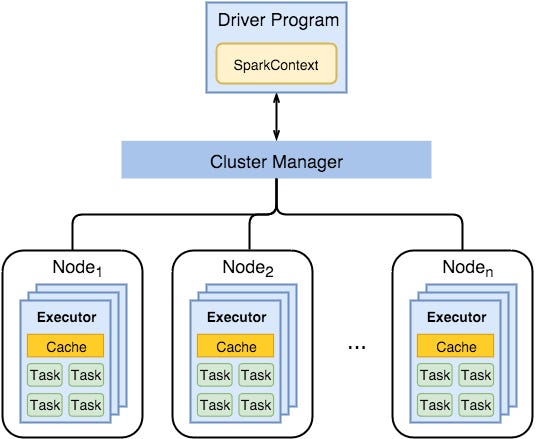
Apache Spark is a distributed computation framework. It is used widely for data-intensive processing tasks. It relies on spreading the computation across multiple nodes in the cluster, and aggregating the results in the end at one node, namely the driver. (More details can be found here.)
Kubernetes
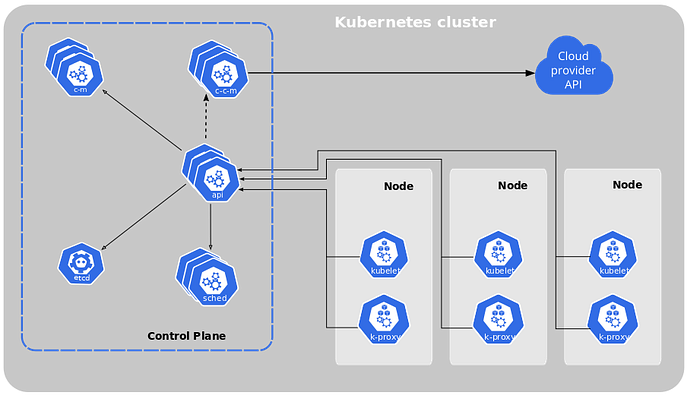
Kubernetes is a portable and extensible container orchestration framework. It has become the de-facto industry standard. It offers flexibility on the type of workloads that can be run on it and where these workloads are run, as long as they are containerized.
Similar to Spark, in Kubernetes, the control plane is responsible for distributing the workload into a set of nodes and making sure it continues to run. In the context of this post, the workload is a single step, e.g. processing step, model training, or model serving. The workload is defined in a manifest file (i.e. YAML file).
Spark on Kubernetes
Executing a Spark job on a Kubernetes cluster is a piece of cake 🍰 (yummy!). One can either use the familiar spark-submit command with the native Spark Kubernetes scheduler, or use spark-operator, an open-source project that facilitates the operator pattern. Here, I will only consider the latter. The spark-operator makes specifying and running Spark applications similar to running other workloads on Kubernetes. It uses Kubernetes Custom Resource Definitions (CRDs) to specify and run them.
Practically, if the operator is installed, one only needs to write a manifest file and use kubectl utility to submit the job to the cluster. The control plane will take care of spinning up the driver and the requested executors.

Kubeflow
Kubeflow is a project dedicated to making ML workflows on Kubernetes scalable and easy to use. It covers from workflow orchestration to model serving stages. There are multiple independent projects composing Kubeflow.
- KFServing is a component used for model deployment and serving. It handles multiple frameworks out-of-the-box. e.g. Tensoflow, PyTorch, ONNX, scikit-learn.
- Training Operators are a collection of operators that help in training ML models. Supported frameworks are: Tensorflow, PyTorch, MXNet, etc.
- Katlib is a component dedicated to hyper-parameter tuning, for neural architecture search.
- KFPipelines helps orchestrate and execute each step of the pipeline in the platform.
Considering again the stages of an ML workflow, Kubeflow is a platform that helps in all those stages. In the processing step, one can perform all sorts of transformations, as it will be shown below. For model training, training operators can be used out-of-the-box or via custom code wrapped in a Docker container. The same logic applies to the serving stage. ML models can be made available via KFServing, or via containerized custom code.
Kubeflow Pipelines
Kubeflow Pipelines provides a platform for orchestrating ML workflows based on containers on top of a Kubernetes cluster. A pipeline is a description of such a workflow. It is composed of components and relations between these components forming a graph. A component during the execution will be translated into a pod. The component is practically a set of code that performs one step in the workflow, e.g. train a model or transforming data. After this component finishes executing, the next one starts.
Components and Component Specification
A Kubeflow Pipeline component is a self-contained code block that performs one of the steps in the pipeline. Each component is packaged as a Docker image or as a manifest file. To execute the component, a component specification must be available. It defines the component’s metadata, interface, and implementation.

Spark on Kubeflow on Kubernetes
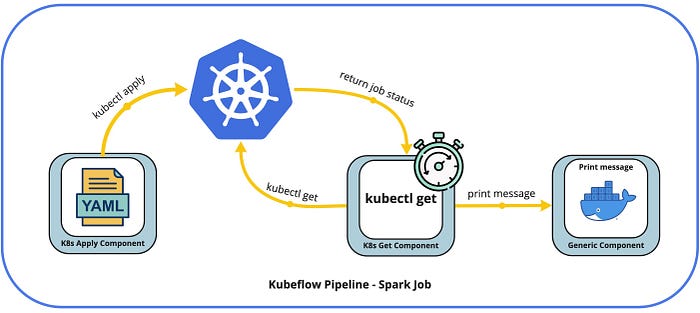
The remaining challenge is to orchestrate a Spark job from Kubeflow and submit it to the cluster. This is solved using pipeline components for kubernetes (Github). These components allow performing commands like kubectl apply, kubectl get, kubectl delete against the cluster during pipeline execution. The k8s apply component starts by loading a manifest file and performs kubectl apply. For the case of a Spark job, it loads the job manifest file and submits it to the cluster. A sparkapplication resource is created in the cluster. Similarly, the k8s get component gets information from the control plane. In the example of a Spark job, it periodically polls the control plane to get the status of the job. Once the job is in COMPLETED state, the pipeline moves to the next step.
Here is an example manifest file for a Spark job. It calculates an approximate value of Pi(π):
The next step is to use the k8s apply component. The input to this component is the manifest file, and the output will be, among others, the sparkapplication name. The following code snippet will make sure the job is submitted.
After the apply operation, the execution engine has to wait for the job to complete before moving on. Using the k8s get component, it gets the application’s state and iterates until the job achieves COMPLETED state. The iteration is done using recursion and the dsl.Condition instruction. The @graph_component decorator indicates recursive execution for the function.
Once the application is completed, the execution will carry on with other pipeline steps.
The full source code used here can be found on Github.
Summary
It is impressive to see how fast the ecosystem in ML is moving and the degree of integration it is facilitating. Now, it is possible to orchestrate Spark jobs with Kubeflow Pipelines running on a Kubernetes cluster. The underlying infrastructure is almost irrelevant. It can be a local PC, a self-managed K8s cluster, or a public cloud provider managed K8s deployment. One only needs to add the building blocks on top.
Great and exciting times are ahead!
At Data Max we help companies truly become data-powered organizations. We strive for technical excellence, and passion for what we do.
